
Why a chatbot?
So far, one of the most promising, foundational uses for AI is as a chat-driven search tool. The core concept is familiar to anyone who’s ever used a smartphone; we communicate with chatbots by exchanging messages.
Unlike a traditional search experience, there are no toggles, checkboxes, or other settings that refine the results—and slow you down. But an intuitive, seamless search experience is only as good as its answers. We wanted to know: How do we answer accurately and responsibly? What is a helpful response to questions without answers? Should our chatbot be limited to the knowledge base? How do we detect and fix errors?
To provide parameters for these critical questions, we anchored our experiment to a real use case with real information. We partnered with Chris Peterson from MIT to build an experimental admissions chatbot for mitadmissions.org.



Finding our approach
Recent advancements have made it possible to adapt AI to our own needs without the costly and time-consuming process of training our own models. One such method is fine-tuning, in which we teach a pre-trained model a new task, also known as transfer learning. Instead of the general-purpose ChatGPT we’re familiar with, we can enforce a specific behavior—generate proper CSV, write a contract, or even compose a haiku.
Our chatbot, however, needs to answer questions based on the knowledge base we provide. While fine-tuning teaches a new task, retrieval augmented generation (RAG) differs from fine-tuning in one fundamental way: it teaches new information. Crafting an effective prompt includes clear instructions for the AI, examples for how its responses should be formatted and most importantly the information with which it should answer the user’s question. This approach offers the simplest and most flexible way of customizing AI with new information.
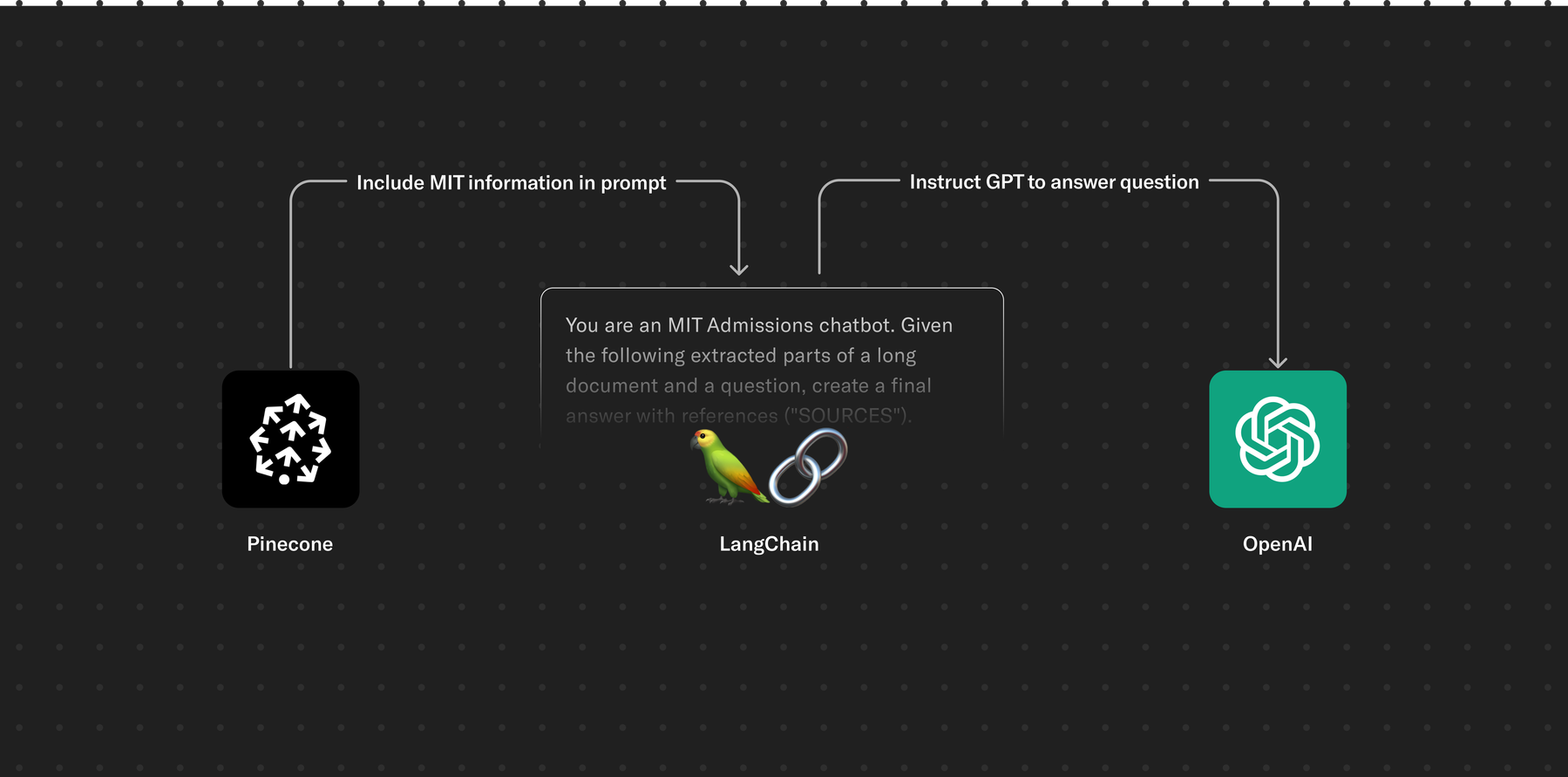
Choosing the right tools
There will always be newer and shinier tools, but a proof of concept was all we needed, so we prioritized choosing basic ones that would get us building early. OpenAI has made their proprietary models easily accessible. Pinecone provides an effortless API for its managed vector databases. Those, along with the flexibility that RAG affords us and popular tools like LangChain, got us to a fully functional chatbot, capable of answering questions and citing relevant sources, within one week.
Conscientious content
Like most of our work, content is a big piece of the puzzle. We scraped the pages of mitadmissions.org to create “vector embeddings” or mathematical representations of the texts’ semantic meaning. Extracting information from embeddings that are most relevant to the user’s question, known as semantic search, improves the quality of our RAG approach.
While AI models are entirely capable of working with raw, unstructured data, it’s worthwhile to synthesize the data. Ensuring each chunk of information in our RAG prompt makes semantic sense and is directly relevant to the chatbot’s tasks can optimize performance, reduce costs, and minimize the odds of ‘hallucinations.’ After all, a chatbot is only as good as the data we give it access to. For products looking to leverage AI, content strategy and editorial process need careful consideration.
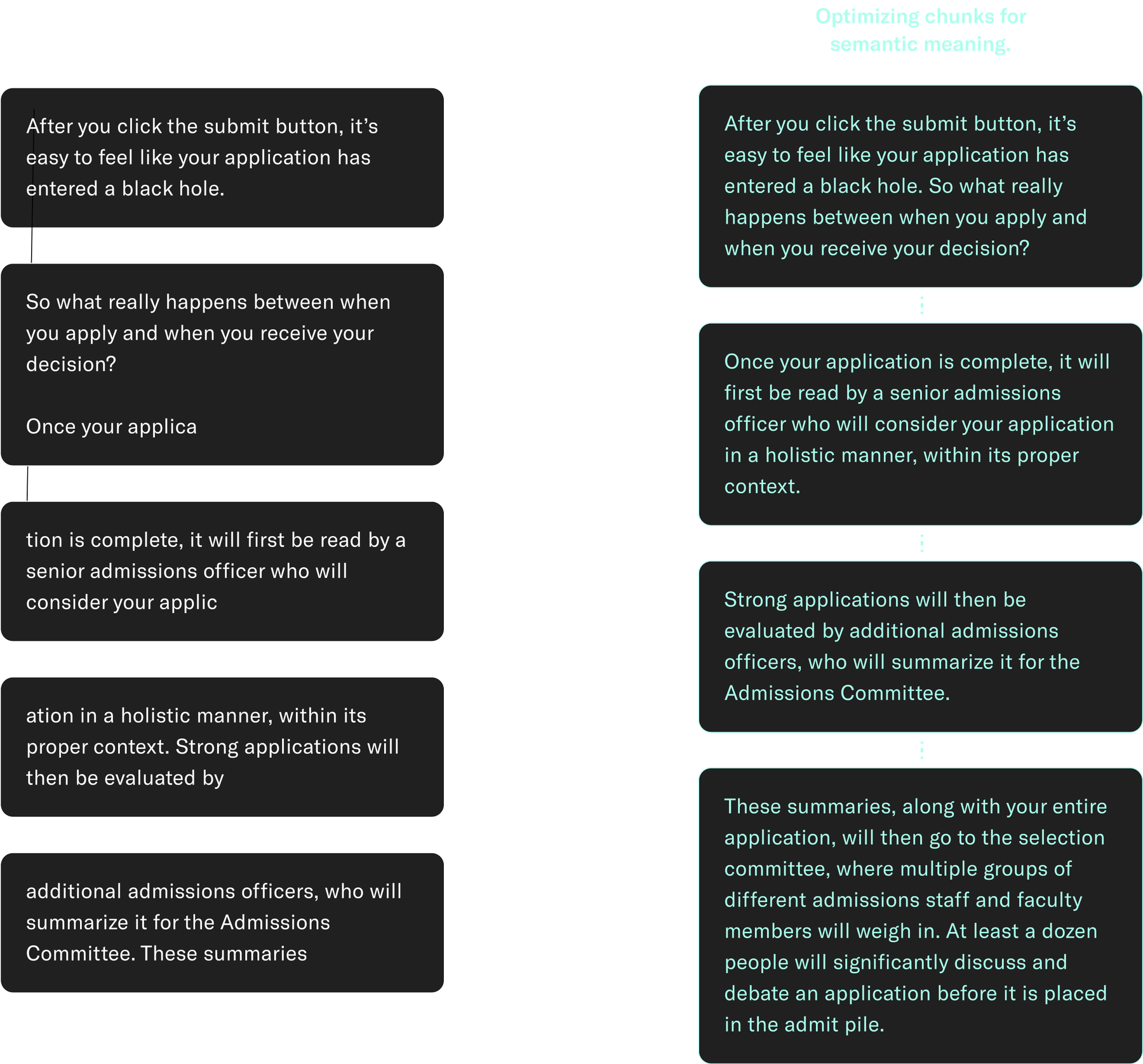
Responsible AI
AI can ‘break’ silently. Unlike obvious, application-breaking bugs in typical software, erroneous answers can slip by unnoticed. AI optimizes its response based on mathematical probabilities, learned from its training dataset. Biases and misinformation originating from the dataset can carry through to its answers without careful curation and supervision. A little prompt engineering helps mitigate but doesn’t entirely eliminate these issues when the inner workings of AI, especially those of proprietary models, are opaque by nature and non-deterministic by design.
Our work has a real impact on the ways people vote, stay informed, or pursue higher education. Affordances communicating the potential for misinformation, human feedback mechanisms, and monitoring are all key ingredients to responsible AI applications.

Test early, often, and openly
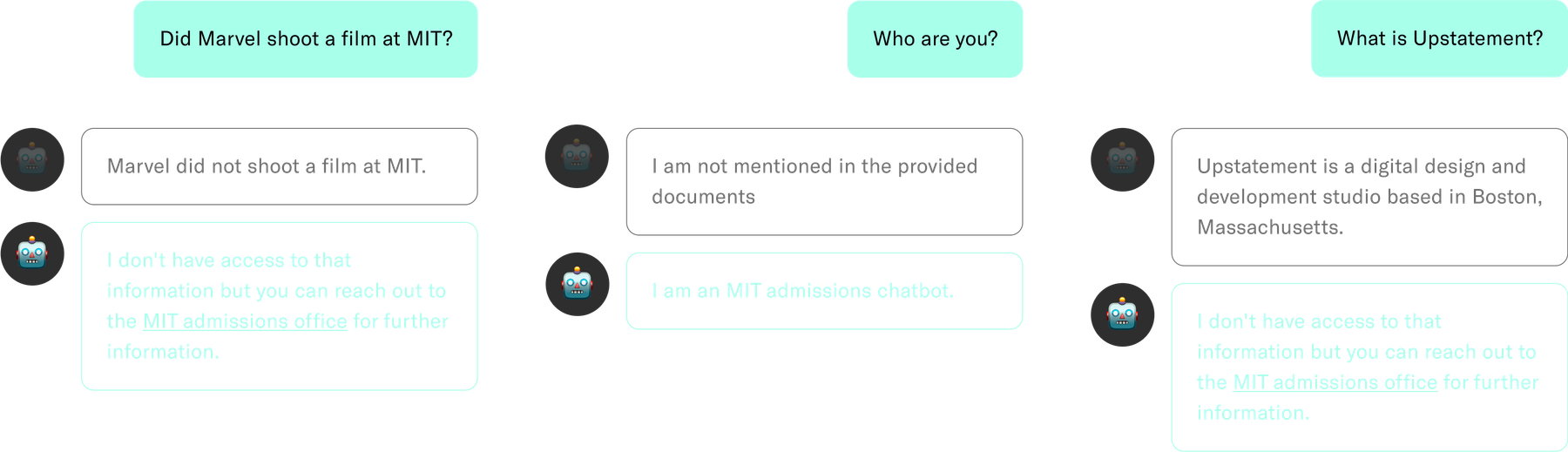
Refining the chatbot was half the battle. As soon as we had a working chatbot, we gave everyone at Upstatement access to the prototype as part of a studio-wide QA (a common practice at Upstatement!). We made numerous improvements—our chatbot now responds in greater detail, operates only in the relevant subject matter, makes conclusions from explicit information only, and provides helpful follow-ups to questions without answers. Establishing a tight feedback loop early in the process helps us find the boundaries we want to set for a product as nebulous as AI.
Part of a greater solution
As we learn about the ways AI works, we’re noticing that above all, it’s flexible. AI isn’t an all-or-nothing solution. There’s a vast range of adoption that organizations can take, from a simple semantic search to a full-fledged chatbot. As thought partners to our clients and their brands, organizations, and platforms, our practice goes beyond building technical AI solutions. A significant part of our job comes before that: determining their appropriate place on the AI-adoption spectrum. Like so many technologies and tools, moderation, strategic thought, and responsible implementation are key.
We’ll be sharing more detailed insights around our chatbot soon, along with takeaways from our other initiatives intended to demystify and leverage AI.




