The Problem
Finding a mobile app CMS to fit our unique requirements
For the past few months, we’ve been building a mobile app with NativeScript-Vue, a JavaScript framework that allows us to quickly build and ship native iOS and Android apps with a single codebase.
The biggest engineering challenge we faced up front was finding a content management system our clients could use to curate the content of the mobile app without needing to touch any code. Our ideal CMS needed to have the following:
- An API to deliver content to the mobile app
- A dashboard for non-technical admins to manage app content and user permissions
- A way to integrate app data with external data via a third-party API integration
Naturally, we started researching what existed on the market for mobile app CMSs — specifically headless CMSs. We looked into several established platforms such as Sanity, Prismic, and Contentful, but none of these seemed to do exactly what we needed for a reasonable price.
Here were some of the notes we took on the shortcomings of those platforms during our R&D phase:
Sanity
- GROQ query language is unfamiliar and would have a learning curve
- We would need to write something custom to import third party data
Prismic
- Their JS API clients weren’t easy to use in a NativeScript context
- They do have a Content Query API, but lack a write API (deal breaker!)
Contentful
- They have a Content Delivery API and Content Management API, but we would still need to write something custom for a third party data integration
- Their pricing plan which jumps from $39/month to a whopping $879/month makes it difficult to recommend, especially when we would still need to write something custom on top of it
The Solution
Building our own custom back-end
Since we couldn’t find a CMS that suited our specific requirements, we decided to build one ourselves! This way, we would be able to tailor our CMS to our app’s unique needs instead of fighting with the restrictions of another platform. Our solution consisted of two parts:
- An admin dashboard for managing content in the mobile app
- A RESTful JSON API to serve content to both the mobile app and the admin dashboard
Nailing down the stack
Spoiler alert: JavaScript, JavaScript, and more JavaScript
Ultimately, our stack looked something like this:
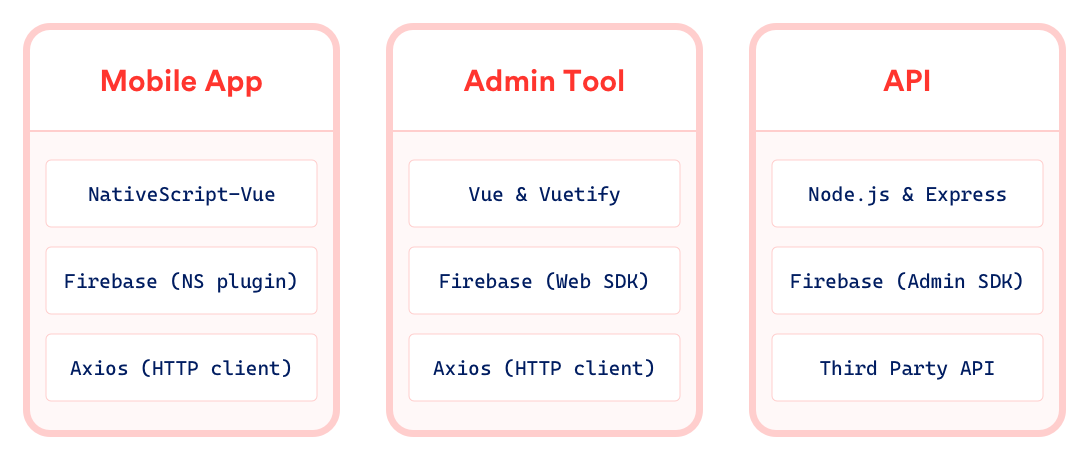
On the front-end of our CMS (the admin tool), we decided to stick with Vue in order to minimize the amount of context switching needed while working across the mobile app and CMS codebases. We also used Vuetify, the material design component framework for Vue, to quickly build out a decent looking user interface.
On the back-end, we went with a tried and true stack for building REST APIs with JavaScript — Node and Express. In both the mobile app and admin tool, we also used Axios, a popular JavaScript-based HTTP client, to interface with our API.
Finally, to round out our mobile app & headless CMS tech gauntlet, we used Firebase as the “back-end to our back-end”. We chose Firebase for several reasons:
- It’s popular and well supported in the NativeScript community
- It comes with several useful cross-platform features out of the box, such as Authentication, Analytics, Cloud Messaging (push notifications), and Cloud Firestore (database). (These saved us a ton of time!)
- It has client-side and server-side JavaScript SDKs with well-documented APIs
Fair warning
In the rest of this post, we’ll mainly be discussing the back-end of our CMS. Maybe one day we’ll write another blog post about our experience building out the front-end with Vuetify and Axios… but in case you were wondering, it was great!
Now let’s take a closer look at how we created an API flexible enough to power both our NativeScript app and admin dashboard…

Building out the API with Express
To scope our API endpoints in a way that would be easy to serve both the mobile app and the admin tool, we set up two main Routers — one for APP routes and one for ADMIN routes.
An example of an app endpoint would be something like /api/feed, which the mobile app would use to fetch a logged-in user’s home feed. On the other hand, an example of an admin endpoint would be something like /api/admin/roles, which the admin tool would use to fetch all possible roles a user could have.
Our routes file looked something like this:
Adding security with middleware
Since our APP and ADMIN routes utilized completely separate controllers, we were able to use router-level middleware functions to guard those controllers. For example, we were able to check if an incoming request was properly authenticated before we allowed the controller to be called to perform a CRUD operation.
In Express apps, middleware functions have access to the HTTP request (req) and response (res) objects, and they can modify those requests and responses as they see fit. You can chain them together and pass requests around, like one big game of hot potato! (hint: the request is the potato 🥔)

For example, most of our admin routes have isAuthenticated and isAdmin middleware set up to handle the requests before they reach the controller.
At a high level, our isAuthenticated function checked a request for a token in the auth header to determine who was making the request, and then our isAdmin function checked if the authenticated user had proper admin privileges.
Here’s a closer look at the isAdmin middleware function:
Since this was an MVP implementation, we decided that a simple authorization scheme — a single admin role that had permission to do everything — would be enough. Therefore, all our isAdmin function really did was check for a truthy isAdmin property on the authenticated user (line 6).
Once the potato 🥔 finally got past our middleware and into our controller, we called the methods that would perform the actual CRUD operations. Here’s what a typical controller looked like:
As you can see on line 7 in the snippet above, the deleteUserById(id) method (which lived on our User model) is where the deletion actually occurred. Now we’re getting to where the magic happened — our models!
Structuring data with models
While we had our middleware and controllers handling HTTP requests and responses, we kept the logic that handled storing and manipulating our data (which lived in Firestore) within our models. All our controllers had to do was simply call those model methods when needed.
We decided to organize our API’s codebase this way in order to maintain a Model-View-Controller (MVC) design pattern. Using this pattern wasn’t just a way for us to keep our code tidy during development, but also a way for future developers to easily grok the codebase.
Using Firestore
Before we start talking about the way our models work their magic, it’s probably best if you have an idea of how Firestore works. For those of you who aren’t familiar, Cloud Firestore is Firebase’s NoSQL cloud database. You store your data in “documents”, which are just JSON objects, and those documents are stored in “collections”, which are containers for your documents. Collections are pretty similar to database tables. You can use these collections to organize your data in a way that’s easy to query.
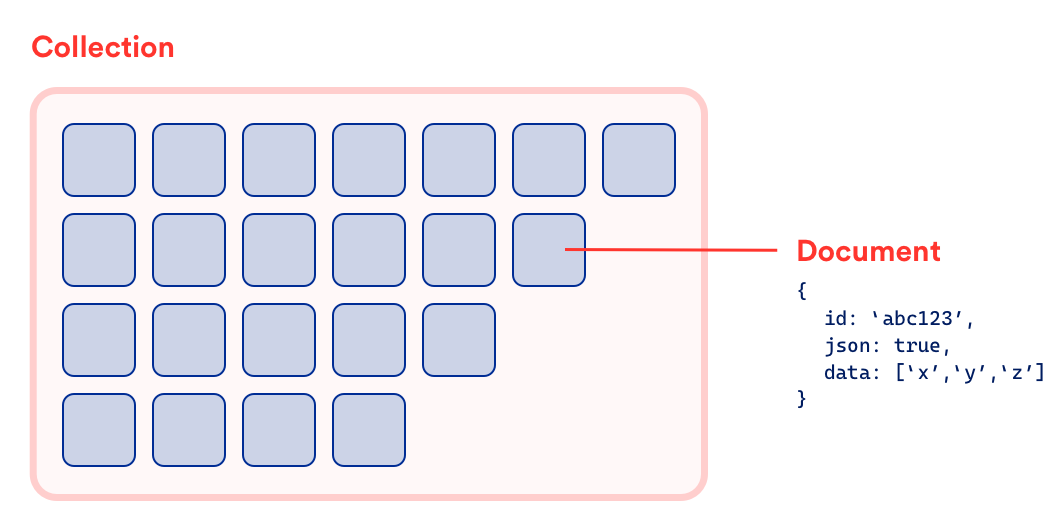
We structured our API in such a way that each collection in Firestore mapped to one of our models. For instance, we had a users collection that corresponded to a User model.
The Base Model
To build out our models, we first created a Base class for our models to extend, which contained common utility methods and data validation logic. To do this validation, we used Joi, a popular JavaScript data validation library. Joi came with a useful API to create schemas (i.e. declaring which fields were what types of data) as well as validate and sanitize objects against those schemas.
Our Base model looked something like this:
As you can see in the constructor, we ran our Joi validation on the creation of a new model instance. If that object didn’t pass validation, our code would throw an error, ensuring no bad data would contaminate our database.
Child Models
On the other hand, our child models contained logic that was meant to manipulate data in their corresponding Firestore collections.
Here is what our User model (which corresponded to the users collection) looked like:
If we wanted to instantiate a new instance of a User model and save it to Firestore, it would be as easy as this:
Now, let’s look at a method that does some of the heavier lifting, such as the deleteUserById() method referenced in the User model above:
We did a few different things in this method:
- We queried for a user document with a specific
idin the Firestoreuserscollection viathis.collectionName() - If it existed, we deleted the document and any other documents related to it with
batch.commit() - We then called
admin.auth().deleteUser(id)to delete the user from Firebase Authentication
Since deleteUserById() is a static method on the User model, we were able to use it anywhere we imported the User model, like you saw in the admin user controller:
This made it easy to keep all database logic siloed in the models while giving us the flexibility to access those methods in other parts of our API. (hint: third party data integrations)
Handling relational data in Firestore
One of the main features of our mobile app was to save and complete tasks, which we populated into the app with our API. We also needed to show relational data for these tasks. For example, under each task on the home feed, we displayed something like:
You, Sam W., and 20 other people did this
To achieve this with a NoSQL database, we had to come up with a way to model data that represented relationships between two (or multiple) collections. So, we decided to create additional collections in Firestore that acted like join tables.
For instance, we had a completedTasks collection where we stored documents containing metadata detailing when a particular user completed a task. These documents contained fields such as the userId of the user who completed the task and the taskId of task. They looked something like this:
Then, when we needed to show this data in a meaningful way (i.e. You and 5 others did this), we would use the taskId and userId to fetch more data to display with additional API calls.
In hindsight, a more traditional SQL database would have made querying relational data easier. Firestore turned out not to be the best platform for storing relational data (especially many-to-many relationships). Creating “join” collections created challenges for us that are usually taken care of with a SQL database — like cascading changes.
For example, when deleting a user, we had to remember to programmatically delete all “join” relationships corresponding to that user in our database, otherwise we would have had stale data floating around. Since functionality like this didn’t come for free in Firestore, the number of documents we needed to query when accessing relational data was inflated.
At the time of writing, Firebase’s free plan comes with 50k reads and 20k writes a day — this sounds like a lot, but when you have multiple developers hot reloading an app, the number of queries add up quick! We had to be mindful about the amount of reads and writes we were committing with each API call, especially when more real data made its way into our app.
Caching user sessions
One way we were able to cut down on reads and writes to Firestore was caching user sessions.
Our mobile app heavily relied on the /me endpoint of our API (which we called the “session” endpoint) to return up-to-date and accurate information about the authenticated user. For example, every time a user saved or completed a task, that data was stored on the user’s session and refetched to keep the app in sync with our database. Most of the way we displayed relational data (i.e. You, Sam W., and 20 other people did this) also relied on the information returned by this session endpoint, so we fetched it frequently.
To cache the user’s session in a way that wasn’t intrusive, we used node-cache, a simple caching module for Node.js. Our approach was simple — every time the session was refetched, we would return the cached session if it existed. If not, we would perform our queries and then store it in the cache for later. To ensure user’s session wouldn’t be cached forever, we set a five minute timeout before the particular key on the cache expired.
Here’s what our cache handling method looked like:
Integrating third party APIs and data
The last (and probably most important) piece of the puzzle for our headless CMS was the third party API integration.
From the start, our client knew that they wanted to have the mobile app integrate with a proprietary platform that they had been collecting data with for many years. This data was important to the app because it made the app more personalized and useful for their target audience. Fortunately, their platform had a REST API we were able to hook into.
Since Firestore was our source of truth for both the mobile app and admin tool, we had to figure out a way to pull down the data from this third party API in a way that would allow it to seamlessly merge with our data. Our solution? Sync scripts and cron jobs! We wrote a handful of scripts and services to hit the third party API via our model methods to safely validate, serialize, and save the data in our database.
One example of this integration took place when a user registered for our app. Based on the given user’s email address, we checked if that user was in the proprietary platform’s database. If they were, we would fetch their specific information (i.e. their role in the organization) and automatically apply it to their user profiles.
Another way we synced data from this third party API was via a script that was run every hour to fetch and sync new data from the proprietary platform. In production, we ended up having a script sync hundreds of records every hour to Firestore. As you can imagine, this sync heavily contributed to our read/write management challenge with Firestore.
TL;DR
We built a headless CMS to power a mobile app from scratch! And it works!
We did some cool things on the API side to make this all happen, including:
- Grouping our endpoints into app and admin routes
- Writing middleware functions to guard our controllers
- Creating a scalable model architecture to structure and handle our data
- Setting up Firebase & Firestore to handle relational data with “join” collections
- Implementing caching to intelligently restrict expensive Firestore queries
- Integrating a third party API to sync important data to our database via cron jobs
Rolling our own custom back-end was hands down the most challenging engineering task of this project. But in the end, we persevered, built some cool stuff, learned a bunch of things, and launched a working app to the App Store and Google Play Store! We’re not able to share the links to those apps just yet, but we’ll be sure to update this post when we are.
If any of this stuff interests you, make sure to check out our engineering page and a bunch of our other engineering nuggets!
Thanks to Mike Burns, Scott Batson, and Mike Swartz for their input!