Identifying a prototypical scenario: college admissions
First we had to consider what kind of application would be most informative. A typical information-dense website require users to find what they’re looking for through navigation or text search. That’s fine; it’s how people are used to navigating content on the web, and it encourages exploration and browsing. But these sites offer utility and their first job is to provide valuable information to users, ideally quickly. AI, especially chat-focused applications, has the potential to change the way that we think about these types of experiences, in which users typically require several different types of information:
- Timely: “When is the next Boston Symphony Orchestra concert?”
- Empirical: “How much are tickets?”
- Real-time data: “Are there any left?”
And sometimes, they need an answer to a challengingly subjective question like “How do I get into MIT?”
With this framing in mind, we decided to collaborate with the admissions team at MIT and use the MIT Admissions website as a prototypical testing ground. The site is a solid use case, packed with loads of information that users rely on for their future. There’s a so much that goes into applying for college, and oftentimes it can be confusing and lead to many questions.
Getting to know our LLM
We started with a baseline. How would an existing model, something like ChatGPT, answer questions about MIT Admissions? So we asked it how to get into MIT. It actually answered fairly well, but it was responding based on general knowledge that the model had been trained on, rather than live data from anywhere on the web. Since it’s not answering from any authoritative source, you might not always get the correct answer.
For example, if we asked it, “Hey, can I get a second bachelor’s degree from MIT?” ChatGPT said, “Yeah, sure, no problem.” On the MIT website, however, they had a different answer. And the reason for this incorrect information is that the underlying LLM that ChatGPT uses has only been trained on general information up until September 2021. There are other models that exist out there, but they all suffer from a similar information gap. If the model isn’t trained on the data that you’re trying to pull an answer from, it won’t give a good answer and it might answer incorrectly altogether.

Training the LLM
So the problem became: how do we get an AI to respond to a user using only the information that we want it to have? Part of our process early on was trying to understand how to get the AI itself to respond with our custom information set—in our case that was the content on the MIT Admissions website. Initially a concept called fine-tuning seemed promising. In theory, you can send training data to an existing model to teach that model about what it should say, loosely illustrated here.
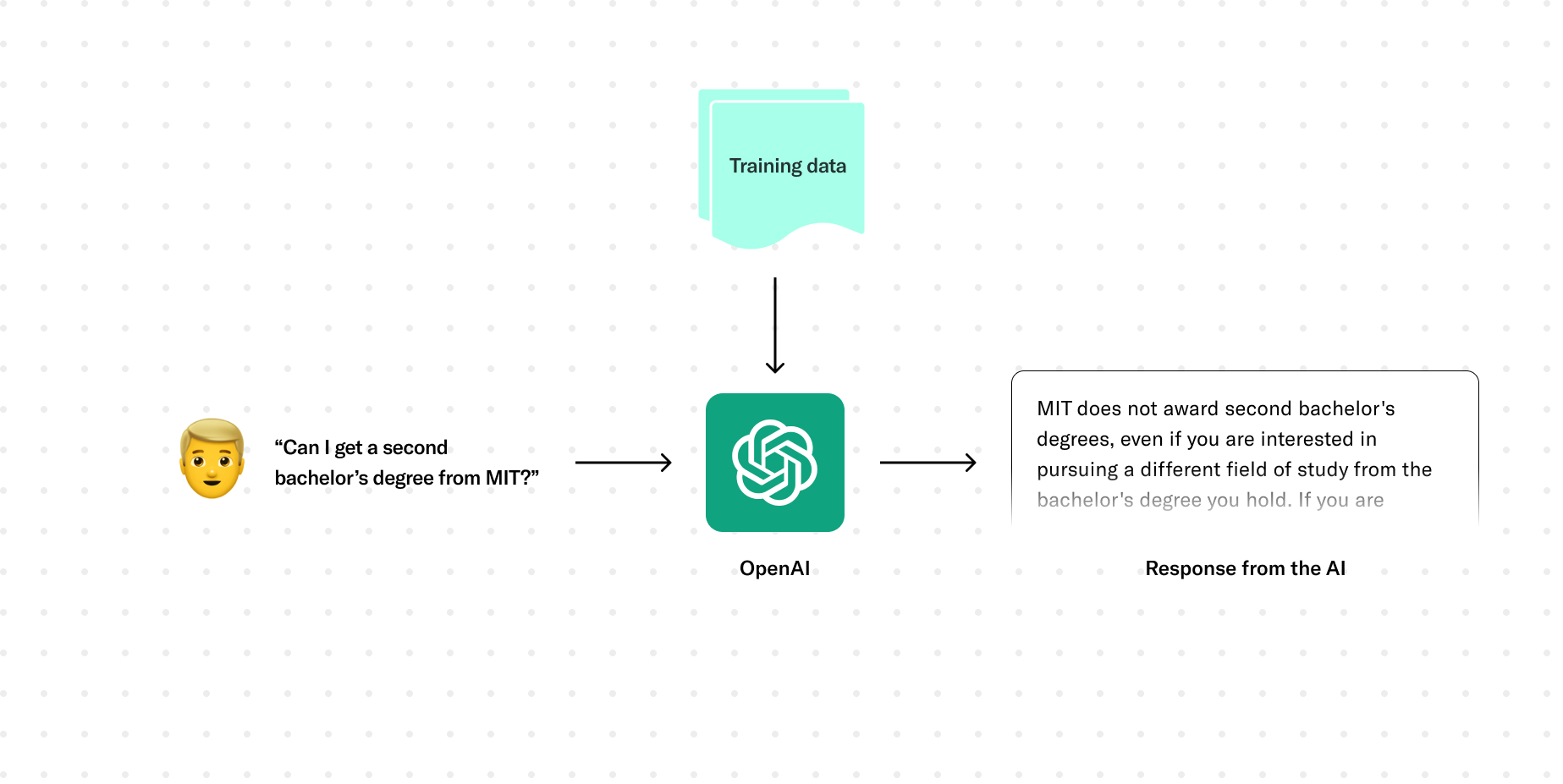
It turned out that that approach is better suited to training a model on formats and patterns as opposed to introducing it to new information altogether. It also didn’t address an important aspect of our project: When applied to a specific application, like the MIT Admissions website, the AI should only respond with information that’s relevant to the MIT Admissions website.
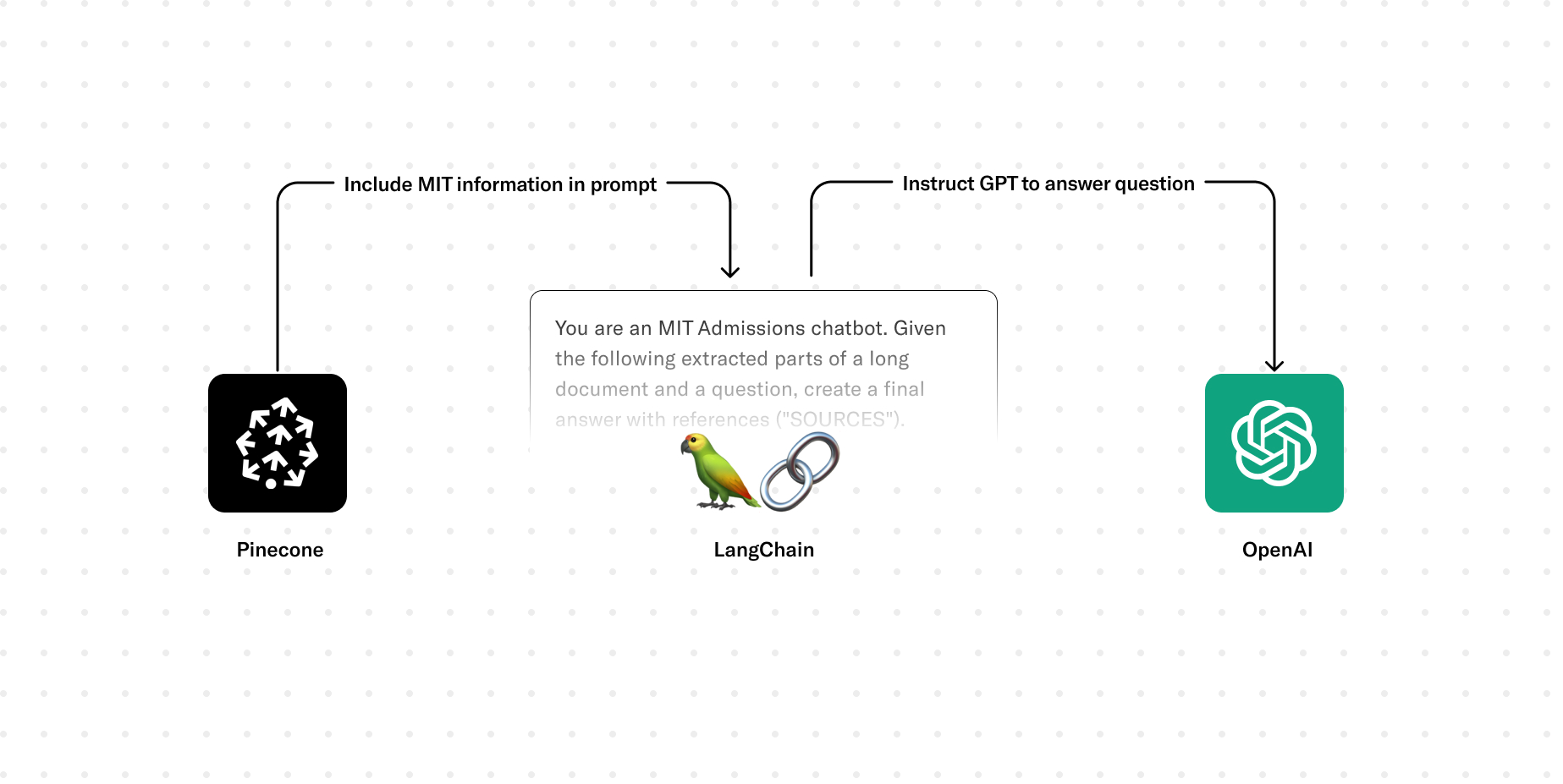
We ended up moving towards an approach called Retrieval Augmented Generation, or RAG. Once again, this is a vastly simplified illustration, but at its core, RAG involves sending relevant context along with a descriptive prompt to the AI to get it to respond in a certain way with certain information. It effectively outlines guidelines on how the AI should respond and what it should respond with. Using the RAG approach led to a slightly different way of thinking about how AI works.
The paradigm that we see most frequently is to ask the AI to generate some content: to answer a question or write a poem, etc. AI rummages through its robot brain and comes up with that answer—but there’s a little bit more to it. What it’s actually doing is predicting the next text in a sequence. This difference is important because it means that the model itself doesn’t have to have been trained on the information that the user is asking it about. It just needs enough context to be able to complete the prompt that a user sent it, so we could provide the information that we needed it to know in the prompt. As it turned out, we weren’t using the AI to come up with the information. We just needed it to understand what it should spit out next and to interact with us in natural language.
RAG in Realtime
So what does this look like in our MIT Admissions example? We needed a way to get the AI its source information from the real-time information on the website. We could send that stuff in the prompt, which meant there would be a few extra steps before getting to the AI itself. The best way to handle this type of thing is to fetch relevant pieces of content from the website based on the user’s message. We could do this with something called vector embeddings, which is a whole mess of computer science-y stuff. But the quick version is that it’s a way to represent text content as points in space. We could compare embeddings against each other to determine how semantically similar they were based on how close their points in space were. In our case, that meant finding content from the MIT Admissions website that was semantically similar to the user’s message.
Our first step was to convert all of the relevant content that we’d want referenced by our AI to vector embeddings and then store those somewhere for later access. We identified pages on the website that we’d want the AI to know about, and then built a script that scrapes content from those pages, creates vector embeddings from that text (we used the OpenAI Embeddings API), then stores those embedding values along with some metadata about the pages themselves into a vector database (we used Pinecone) that we can query against later. This type of script could be set up to run whenever content is updated or added in a CMS. But the important thing is that the vector embeddings themselves existed in the database and they were up-to-date with the latest content that was live on the website.
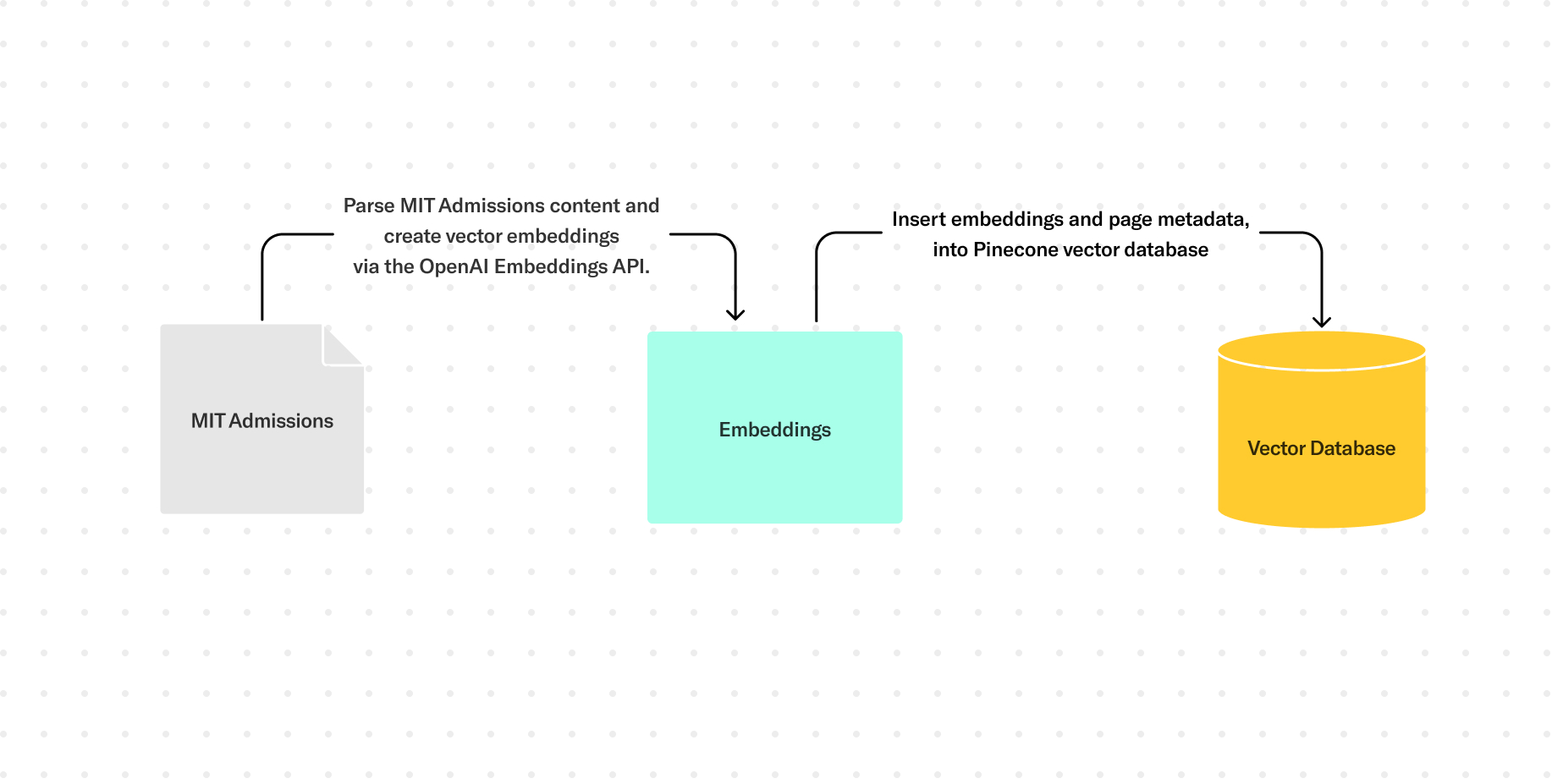
Once the source information is stored and accessible as vector embeddings, the actual interaction with the chatbot goes a little bit like this: The user’s text input is converted into another vector embedding, again, via the OpenAI Embeddings API, which is used to query the vector database itself to return semantically similar content matches. Again, the idea is that we get content from the website that is relevant to the user’s input. These records could also include metadata like the page URL, which we could also send with the prompt for additional formatting. Those results are used to generate the prompt itself, which is sent to the AI to generate the AI’s response, which is then returned to the user.
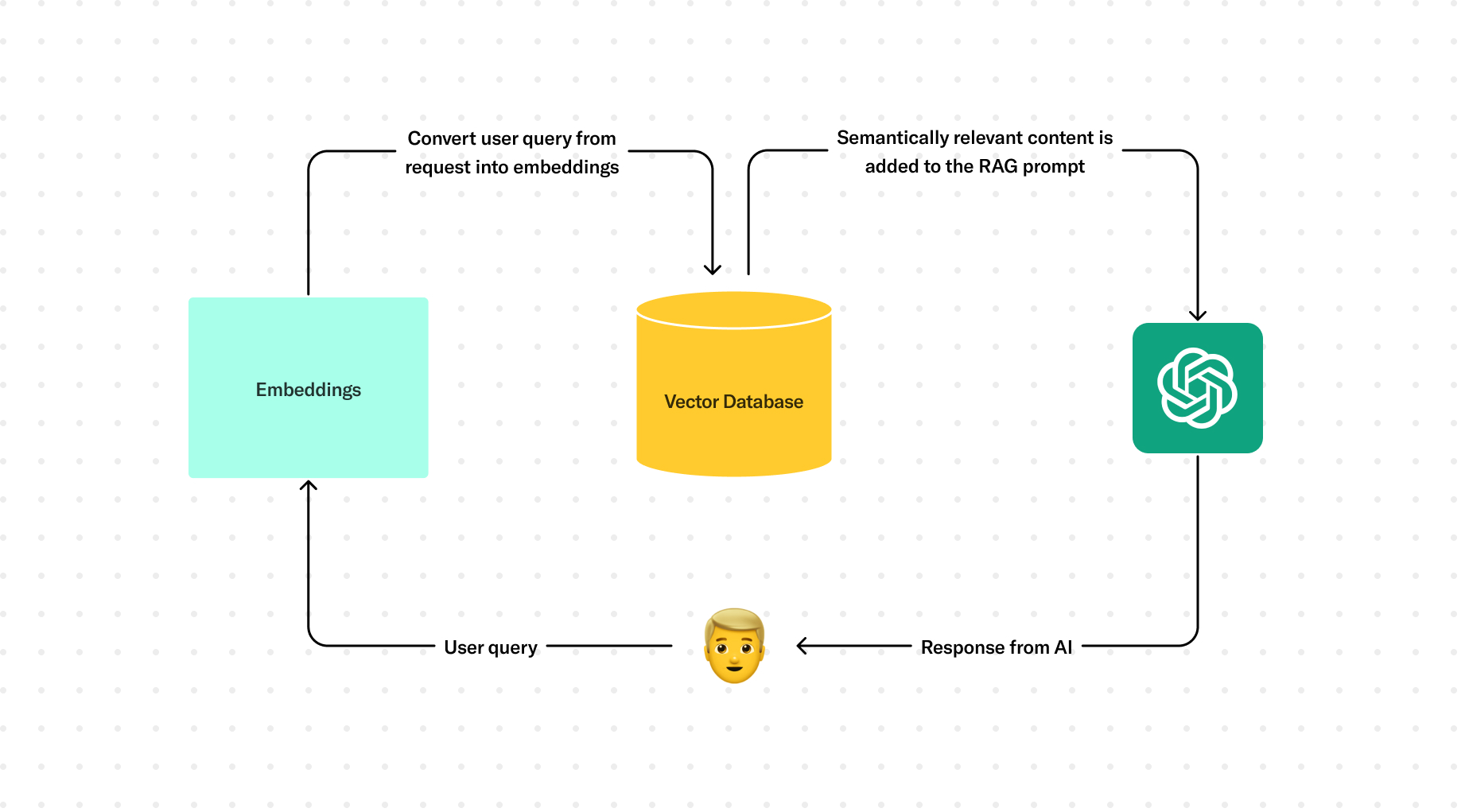
That’s a pretty high level look of the process, so let’s focus a bit on the prompt that actually gets sent to the AI. Once we have our relevant website content, we want to send all of that along as well as instructions for how we want the AI to respond. Our prompt consists of three parts.
1. First, we’ll give it instructions to follow. We can give it a sense of identity, directions for what to do, and parameters for the response, down to how to format it. For example: Always return sources. This is also the spot to specifically call out edge cases. We want our chatbot to respond only with information about MIT Admissions, and we certainly don’t want it to make stuff up. So this is the part where we say, “Hey, if we didn’t send you information relevant to the user’s message, then say that you don’t have the information. Don’t try to make up an answer.” This is in service of trying to scope the responses exclusively to our Admissions content.
You are an MIT Admissions chatbot. Given the following extracted parts of a long document and a question, create a final answer with references ("SOURCES").
If you don't know the answer, just say that you don't have access to relevant information. Don't try to make up an answer.
ALWAYS return a "SOURCES" as a comma separated list in your answer.
2. The second part of the prompt includes what’s called few-shot learning. This effectively allows us to give the AI a few examples of what we’d expect it to respond with and the pattern that we’d like it to follow. This part isn’t strictly necessary. Realistically, our chatbot would probably respond pretty well using just the system instructions and the completion prompt, which we’ll discuss soon. But this helps to show the AI examples of our specific requirements, like that formatting around always returning sources, and edge cases, like the answer not existing in the source content. It’s worth noting that the contents of these examples don’t have to be relevant to the content that you’re trying to retrieve. This step is mostly about formatting and giving the AI something to base the responses on, which means that these examples are consistent for every prompt that we send to the AI throughout the application.
QUESTION: Which state/country's law governs the interpretation of the contract?
———————————
Content: This Agreement is governed by English law and the parties submit to the exclusive jurisdiction of the English courts in relation to any dispute (contractual or non-contractual) concerning this Agreement save that either party may apply to any court for an injunction or other relief to protect its Intellectual Property Rights.
Source: 28-pl
Content: No Waiver. Failure or delay in exercising any right or remedy under this Agreement shall not constitute a waiver of such (or any other) right or remedy.
11.7 Severability. The invalidity, illegality or unenforceability of any term (or part of a term) of this Agreement shall not affect the continuation in force of the remainder of the term (if any) and this Agreement.
11.8 No Agency. Except as expressly stated otherwise, nothing in this Agreement shall create an agency, partnership or joint venture of any kind between the parties.
11.9 No Third-Party Beneficiaries.
Source: 30-pl
Content: (b) if Google believes, in good faith, that the Distributor has violated or caused Google to violate any Anti-Bribery Laws (as defined in Clause 8.5) or that such a violation is reasonably likely to occur,
Source: 4-pl
———————————
FINAL ANSWER: This Agreement is governed by English law.
SOURCES: 28-pl, 30-pl3. Finally, we get to the completion prompts. This is where we include the user’s query and all of the content that we retrieved from the vector database earlier. These are the pieces of content that are most semantically similar to the user’s message. Each content block includes a source, which is the URL where that content lives on the website. This is metadata that we can store with the vector embeddings and should be returned with the AI’s response. If you’ll remember earlier, we specifically told it to return a list of sources in the system instructions. The goal with including sources here is to encourage trust in the chatbot by showing that it’s not making stuff up. It’s actually pulling the information from a specific page on the site.
The final line of the prompt is the answer. Based on the instructions in step one and the examples that we provided in step two as part of the few-shot learning, the AI reaches this point and says, “Okay, this is where I generate text that I think will complete this full thought.” For every interaction with our chatbot, we send this style of prompt out to the AI for it to respond to. The only thing that really changes is the completion prompt at the end, which is where we pass the user’s message and the relevant pieces of content. The instructions are always the same. The few-shot examples are always the same. The response should be a relevant, factually correct answer that also contains a list of sources, in this case the pages on the site where the information came from.
QUESTION: How much does MIT cost?
———————————
Content: We are committed to helping our students pay for their MIT education. We award aid that meets 100% of your demonstrated financial need.
The big picture
The full price of an MIT education is $79,850. However, most students pay far less than that. We offer full-need financial aid, which means we meet 100% of demonstrated financial need for all admitted students for all four years of your undergraduate career.
The average annual price paid by a student who received financial aid was
$19,59901
2021–2022 is the last year for which we have full data. This number includes Pell grants and scholarship grants from non-MIT sources.
in the 2021–2022 academic year. 85% of students graduate debt free.
Source: https://mitadmissions.org/afford/cost-aid-basics/access-affordability/
...
———————————
FINAL ANSWER:If we use the deployed application, we can ask it the same question: How much does MIT cost? The wording won’t be exactly the same as the source. The generative aspect of the AI means that it has some independent thought around the exact language of its response, but the important stuff should always still be there: the full price, info about financial aid, the source. And so we can continue to interact with this as we would any other chatbot, including asking it more open-ended questions, and it will still pull its response from the content that we provide for it.
Naturalized Conversation
We also implemented some other expected features of a chatbot, like context awareness that enables the AI to know about previous messages and what we’ve been talking about. That way a user doesn’t always have to explicitly mention MIT in their message. The whole application is intended to be a conversational interface, so you can converse with it as you would any other chatbot or really any other person. The goal is to make it feel human in nature.
This is not a candidate for production or something the MIT Admissions team is even considering launching. It’s all theoretical at this point, but this helped us understand what an application might look like in the real world. There’s a lot of potential in this type of interaction, but there are still a lot of questions to answer. We’ll be posting updates as our Discovery AI initiative progresses—for now, check out an early case study or take a look at our AI art direction practice.
Discovery AI is Upstatement’s ongoing exploration of AI’s impact on how we create, access, and use information.


